RESEARCHMachine learning was uncharted territory for all team members when we first began. In order to submerge ourselves in this space, we conducted in-depth primary and secondary research before meeting up with our stakeholders at Bloomberg. This included reviewing literature and interviewing Data Scientists, ML Engineers, and Project Managers.
With a shared ML language, we then conducted various research methods to try to understand and visualize where the biggest pain points were for our stakeholders and where we could bring the most value.
Domain knowledge
We researched academic papers on machine learning experiment management to gain domain knowledge and better understand the problem space. The literature review was also used to discover existing pain points and varying perspectives.
Furthermore, we reviewed literature from adjacent problem spaces that deal with tracking multiple moving parts of a complex system, such as healthcare. This was done to help keep our perspective open and create ideas outside of common practices. The literature review also informed and reinforced our proposed pain points of the ML process.
There was one paper in particular that stood out to us. Its web-based dashboard summarized model performance in a bar chart as well as a scatterplot that displayed the relationships between hyperparameters and performance metrics.
Key Takeaways:
i
It is recommended to utilize different visualizations such as charts and scatterplots to compare experiment results and provide different perspectives of the data.
ii
Hierarchy is key. Organization of a project in file format allows for efficient access of results.
Runway: machine learning model experiment management tool by Jason Tsay, Todd Mummert, Norman Bobroff, Alan Braz, Peter Westerink, Martin Hirzel
Faculty
We aimed to further our domain knowledge in both Machine Learning and Experiment Management software by interviewing faculty at Carnegie Mellon. We interviewed Professor Jason Hong to discuss topics on Machine Learning and Professor Majd Sakr to review an ML experiment management project occuring in the Computer Science department.
Professor Sakr provided us with tips he learned from his projects which we kept in mind during our research phase. Sakr found the experiment management process to be broad so he recommended focusing on a specific area to provide strong targeted value. He also warned that the designs we test should be tested on the users who will be using the end product. These considerations helped us orient as we progressed into research.
Some findings:
i
Machine learning experiments are highly complex and nuanced. Each experiment can be the replication of the previous one. Instead of trying to design for the entire workflow, it may be more beneficial to zoom in on one specific use case.
ii
Professor Hong challenged us to answer these questions in our research:
What do different teams do? What do they want to see differently from each other? Who manages the cluster? Who has the priority?
Model Users
We then interviewed Machine Learning graduate students at Carnegie Mellon. These interviews provided us with a foundation early in the process in laying out the machine learning workflow.
We noticed there was a gap between Machine Learning in academia vs. industry. There wasn’t a high demand for collaboration as students often worked in silos. Their experiment sprints were smaller in scale in terms of amount of data collected.
Students also didn’t have to worry about production of their models. While keeping these differences in mind, the model user interviews provided us with useful domain knowledge of the ML workflow process.
Some findings:
i
In academic ML, there is less emphasis on building stable production models and more on exploration.
ii
Student experiments were generally on a smaller scale and would not require as many resources.
iii
A smaller scale equates to less requirements for tracking metrics.
iv
Academic Machine Learning workflows were similar to industry in the artifacts and tools they used for exploratory research.
In this section we analyzed 4 machine learning management software and provided a breakdown of the key features/capabilities offered. We have guild.ai, comet.ml, neptune.ai, and mlflow.org.
Their features include:
i
Tracking (metrics, artifacts, success rates, start/end times of experiments) Reproducibility (ensuring experiments can be reproduced based on artifacts provided)
ii
Compare experiments (having a visual comparison what works and what doesn’t)
iii
Collaboration amongst teams (ability to see what members of the teams are currently working on to avoid duplication of efforts)
From this, we gathered that there isn’t a tool that effectively encompasses all the capabilities. This raises two questions for our research in the space of experiment management at Bloomberg:
Are we designing into a white space or are we working on top of something pre-existing?
What are the workarounds the engineers are currently adopting?
01Literature Review
We researched academic papers on machine learning experiment management to gain domain knowledge and better understand the problem space. The literature review was also used to discover existing pain points and varying perspectives.
Furthermore, we reviewed literature from adjacent problem spaces that deal with tracking multiple moving parts of a complex system, such as healthcare. This was done to help keep our perspective open and create ideas outside of common practices. The literature review also informed and reinforced our proposed pain points of the ML process.
There was one paper in particular that stood out to us. Its web-based dashboard summarized model performance in a bar chart as well as a scatterplot that displayed the relationships between hyperparameters and performance metrics.
Key Takeaways:
i
It is recommended to utilize different visualizations such as charts and scatterplots to compare experiment results and provide different perspectives of the data.
ii
Hierarchy is key. Organization of a project in file format allows for efficient access of results.
Runway: machine learning model experiment management tool by Jason Tsay, Todd Mummert, Norman Bobroff, Alan Braz, Peter Westerink, Martin Hirzel
02Interviews with Faculty & Model Users
Faculty
We aimed to further our domain knowledge in both Machine Learning and Experiment Management software by interviewing faculty at Carnegie Mellon. We interviewed Professor Jason Hong to discuss topics on Machine Learning and Professor Majd Sakr to review an ML experiment management project occuring in the Computer Science department.
Professor Sakr provided us with tips he learned from his projects which we kept in mind during our research phase. Sakr found the experiment management process to be broad so he recommended focusing on a specific area to provide strong targeted value. He also warned that the designs we test should be tested on the users who will be using the end product. These considerations helped us orient as we progressed into research.
Some findings:
i
Machine learning experiments are highly complex and nuanced. Each experiment can be the replication of the previous one. Instead of trying to design for the entire workflow, it may be more beneficial to zoom in on one specific use case.
ii
Professor Hong challenged us to answer these questions in our research:
What do different teams do? What do they want to see differently from each other? Who manages the cluster? Who has the priority?
Model Users
We then interviewed Machine Learning graduate students at Carnegie Mellon. These interviews provided us with a foundation early in the process in laying out the machine learning workflow.
We noticed there was a gap between Machine Learning in academia vs. industry. There wasn’t a high demand for collaboration as students often worked in silos. Their experiment sprints were smaller in scale in terms of amount of data collected.
Students also didn’t have to worry about production of their models. While keeping these differences in mind, the model user interviews provided us with useful domain knowledge of the ML workflow process.
Some findings:
i
In academic ML, there is less emphasis on building stable production models and more on exploration.
ii
Student experiments were generally on a smaller scale and would not require as many resources.
iii
A smaller scale equates to less requirements for tracking metrics.
iv
Academic Machine Learning workflows were similar to industry in the artifacts and tools they used for exploratory research.
03Competitive Analysis
In this section we analyzed 4 machine learning management software and provided a breakdown of the key features/capabilities offered. We have guild.ai, comet.ml, neptune.ai, and mlflow.org.
Their features include:
i
Tracking (metrics, artifacts, success rates, start/end times of experiments) Reproducibility (ensuring experiments can be reproduced based on artifacts provided)
ii
Compare experiments (having a visual comparison what works and what doesn’t)
iii
Collaboration amongst teams (ability to see what members of the teams are currently working on to avoid duplication of efforts)
From this, we gathered that there isn’t a tool that effectively encompasses all the capabilities. This raises two questions for our research in the space of experiment management at Bloomberg:
Are we designing into a white space or are we working on top of something pre-existing?
What are the workarounds the engineers are currently adopting?
Field Research in New York
01
OverviewIn order to answer the emerging questions, we started planning a visit to Bloomberg’s New York office and meeting our primary users in person — the Machine Learning Engineers, Data Scientists, and Product Managers.
We prepared an interview guide for two alternate research methods — contextual inquiry (building a master-apprentice relationship with our interviewee) and semi-structured interviews (directed narrative).
During the planning phase, we accounted for the spatial layout of the office environment while drafting our questions and activities. Another important aspect we considered was how much time away from work the users could take given our trip coincided with Valentine’s day and the beginning of a weekend. We realized that people might want to leave early for the day and therefore decided to carry chocolates and greeting cards to thank the participants for their generosity with time.
02
Sense MappingWe gathered our notes from the New York trip and color coded them across different teams on an excel sheet. Using affinity clustering, we grouped these notes across need-based user statements.
This exercise was pivotal for us in identifying the core framework for the Machine Learning workflow. The new framework helped us draft a sequence model workflow exercise for finding patterns during future research methods. We also uncovered gaps and missing information in the flow that needed further inquiry through semi-structured research in the form of a survey.
What did we learn?
01Identified follow-up methods to better understand the machine learning workflow
02Uncovered gaps and missing knowledge we needed to further research through semi-structured interviews
Current State Analysis
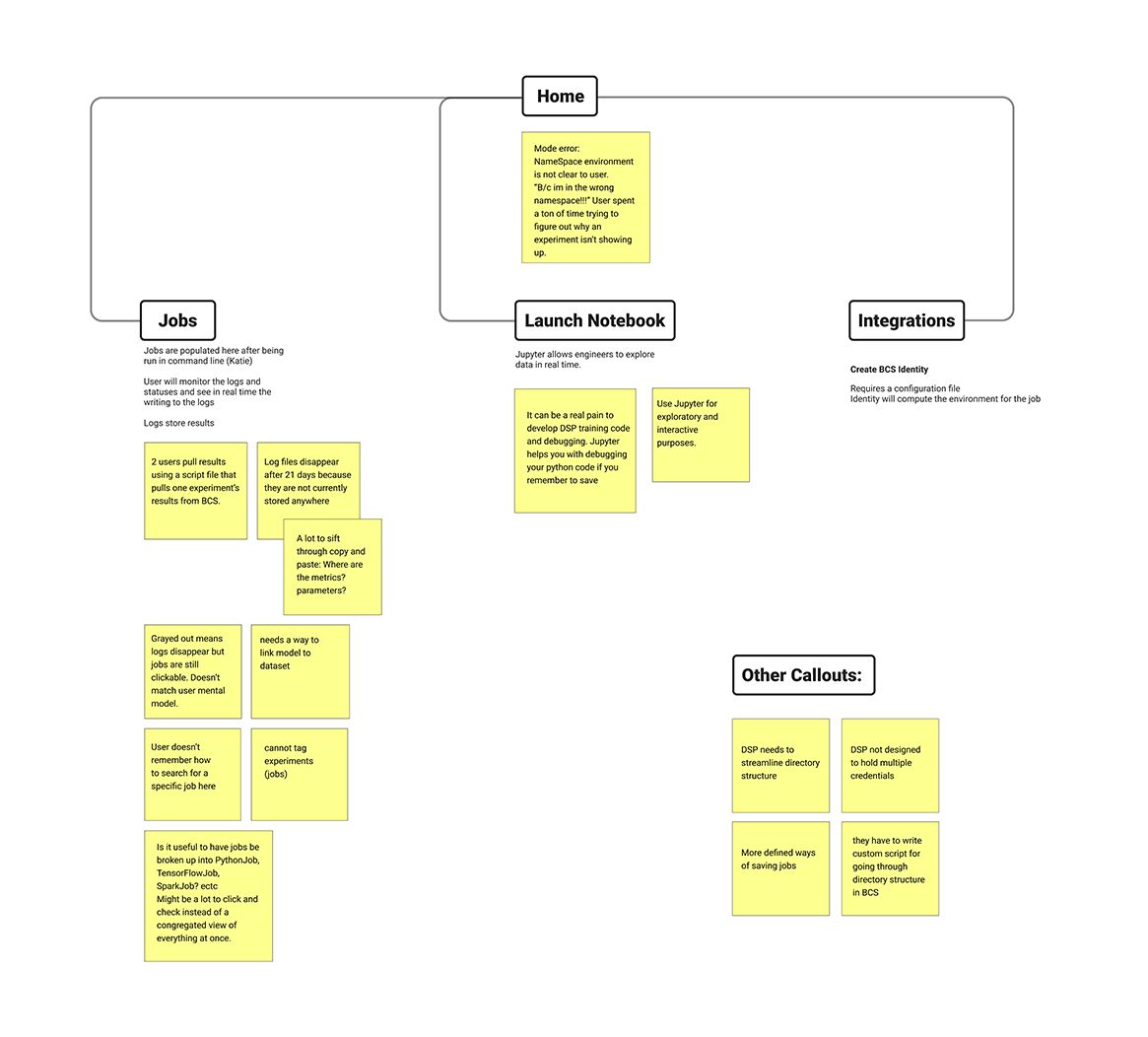
The current state of machine learning management at Bloomberg is conducted on the Data Science Platform (DSP). The DSP’s main function is to run ML experiments by connecting data and models with GPU then displaying the results in logs.
We aim to understand the advantages and the wish list for the DSP during our interviews with ML engineers. The findings will drive our design for the future state.Identified pain points:
i
Lack of experiment comparison.
ii
It is difficult for users to keep track of the experiment results on Spectro because log files disappear after 21 days since they are not currently stored anywhere.
Users are less inclined to use this feature knowing it will disappear after 21 days.
"My project might last longer than 21 days."
iii
Experiment homepage has pages and pages of experiments. It’s hard for user to have a glanceable view of which experiment is which.
What were the metrics? Parameters?
"I want to be able to filter experiments by application type, time period, hyperparameter and accuracy."
iv
NameSpace environment is not clear to user.
User spent a ton of time trying to figure out why an experiment isn’t showing up.
"B/c im in the wrong namespace!!!"
×
SYNTHESIS
Machine learning was uncharted territory for all team members when we first began. In order to submerge ourselves in this space, we conducted in-depth primary and secondary research before meeting up with our stakeholders at Bloomberg. This included reviewing literature and interviewing Data Scientists, ML Engineers, and Project Managers.
With a shared ML language, we then conducted various research methods to try to understand and visualize where the biggest pain points were for our stakeholders and where we could bring the most value.
01Ineffective tracking leads to further issues in documentation and discoverability.Through affinity diagramming and workflow analysis, we’ve found that the limitations of the current tools available for tracking has negative, cascading effects on various different aspects of ML engineers’ workflow--namely documentation and discoverability.
Much like a domino effect, tracking is the bedrock for documentation and discoverability. If tracking has issues, the problems will transfer over to other realms of ML engineers’ workflows.
02The machine learning workflow is comprised of three interdependent components, data, code, and results, which are all reliant on effective tracking.We synthesized our interviews with the Machine Learning engineers at Bloomberg, to draft a model of their machine learning workflow. The design of this model is categorized in three distinct stages - Data, Code and Result based on the three artifacts that machine learning engineers have to tackle with.
03Because of system limitations, machine learning engineers resort to developing their own workarounds to substitute workflow challenges.With a lack of set standards and support, ML engineers have resorted to developing their own workarounds, making it difficult to collaborate across teams. Yet workarounds have become so internalised at Bloomberg that they almost seem like an inherent part of the process.