CHI Preview: Variolite: Supporting Exploratory Programming by Data Scientists
When you are given a task with a number of possible approaches and no clear requirements, how do you get started? When faced with building software to solve an open-ended problem, it’s often impossible to fully design what to build upfront. Programmers often need to experiment with ideas by writing code, running it, and examining the result. This process of iteratively writing code in order to design and discover the goals of a program is a process called “exploratory programming.”
A team of researchers from Carnegie Mellon University and the Oregon State University are studying exploratory programming. HCII Ph.D. student Mary Beth Kery, Professor Brad Myers and Oregon State undergraduate Amber Horvath ran a study involving 70 data scientists. They conducted semi-structured interviews and used surveying techniques to explore how ideation is carried out using source code.
They observed that data scientists often write code to pursue an idea or analysis without a clear path or well-defined goal. Because of this, they will frequently experiment by repurposing code or building off code used from a previous idea. Programmers who practice ideating or experimenting through code often manage the abundance of code they generate using informal version control, such as commenting-out code or creating many files with similar names, which requires that they keep their own complex mental maps.
Given this strategy, and the number of different experimental versions of their own code that data scientists generate, Kery, Myers and Horvath expected to see data scientists benefiting from the standard version control software. Instead, some programmers actively avoided using them, even people who use the same version control software for other tasks.
The paper notes that, "Only 3 out of 10 interviewees chose to use software version control for their exploratory analysis work, although 9 of 10 did use VCSs…for other non-exploratory projects."
In their paper, "Variolite: Supporting Exploratory Programming by Data Scientists," Kery, Myers and Hovarth found that data scientists avoid using standard version control systems for their explorations for a number of reasons, including the feeling that the VCSs are too heavy-handed for what they needed.
Since formal version control systems do not meet users' needs, many take to informal efforts, including commenting out code to store alternate versions of code. This informal process introduces a new set of challenges for data scientists primarily around confusion.
Managing the naming conventions, code context and locations, and inconsistent alternatives require programmers to create a complex and detailed map in their heads for their code management. In the paper, which was awarded an Honorable Mention at the ACM SIGCHI 2017 Conference, Kery and team introduce their tool, Variolite, which supports local version control and a more natural usage pattern for data scientists.
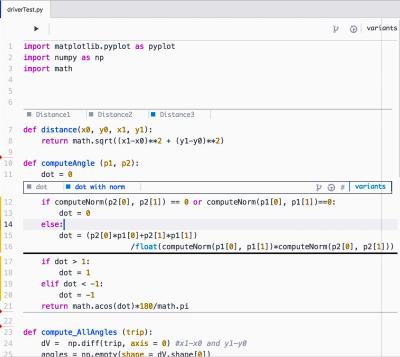
Variolite is a prototype tool implemented in CoffeeScript and CSS, using Atom editor's package framework. It introduces functionality called variant boxes, where users can select code to create alternative versions by drawing a box around it.
Users can control which code is active and which is stored for possible use later with the simple switch of the active tab. Users are also not limited to the type of iterations. They can produce alternatives of a file, group of functions or even a single line of code with the same process.
To learn more about the prototype tool, Variolite, read the complete paper here